There are hundreds of different measures of partisan advantage, most
typically attempting to describe “partisan symmetry”. This vignette
introduces some of the most common and most important measures of
partisan advantage. See the vignette “Using redistmetrics”
for the bare-bones of the package.
We first load the redistmetrics package and data from
New Hampshire. For any function, the shp argument can be
swapped out for your data, rvote and dvote for
any two party votes, and the plans argument can be swapped
out for your redistricting plans (be it a single plan, a matrix of
plans, or a redist_plans object).
library(redistmetrics)
data(nh)For illustration purposes, we utilize what is often called the
“normal Democratic vote” ndv and the “normal Republican
vote” nrv which are the averages of the recent elections by
party. For most purposes beyond basic description, you would want to
compute these scores for several elections and then average the
scores.
This is a brief introduction to the measures included in the package. For a more thorough, yet still friendly introduction, we recommend Katz, King, and Rosenblatt (2020).
Democratic Vote Share
The Democratic vote share is the vote share by district under fixed Democratic and Republican votes.
All scores range from 0 to 1, where a higher proportion indicates a more Democratic voters in a district relative to Republican voters.
Formally, for each district, this can be written as:
The Democratic vote share can be computed with:
part_dvs(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] 0.4387596 0.5378342Democratic Seats
Democratic seats is the number of seats that Democrats would win under fixed Democratic and Republican votes.
All scores are between 0 and the number of districts.
Formally, this can be written as:
Democratic seats can be computed with:
part_dseats(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] 1 1Partisan Bias
Partisan bias is the deviation from partisan symmetry at a voteshare .
Positive scores indicate bias in favor of Republicans, while negative scores indicate bias in favor of Democrats. Scores are in the range of -1 to 1.
Formally, this can be written as:
Partisan Bias can be computed with:
part_dvs(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] 0.4387596 0.5378342The argument (for ) can be set for any value in to and is by default.
Responsiveness
Responsiveness describes the slope of the implied seats-votes curve by an election. A higher score implies that a districting plan is more likely to change given a change in vote distribution.
Formally, this can be written as:
where is a user-specified bandwidth.
Responsiveness can be computed with:
part_resp(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] 0 0The argument v can be set for any value in
to
and is
and the bandwidth is
by default.
Note that the responsiveness can be very sensitive to
bandwidth. For example, in the above we get values of 0. If
we widen the bandwidth, the results change drastically!
part_resp(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv, bandwidth = 0.1)
#> [1] 10 10Declination
The declination describes the difference in the angle of two line through ordered an ordered scatter plot of Democratic and Republican votes, where one line is fit to the center of mass for each.
The normalized declination can take on values from -1 to 1, where a negative score indicates a pro-Democratic bias and positive score indicates a pro-Republican bias. The declination is not defined when one party wins all seats. When not normalized, the scores are in radians, and the negative and positive interpretations stay the same.
Formally, this can be written as:
introducing as the average Democratic voteshare in Democratic-won districts and as the average Democratic voteshare in Republican-won districts. is the Democratic seat share.
Declination can be computed with:
part_decl(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] -0.01022629 -0.01022629By default, declination is normalized to a fraction of an angle, via
the normalization argument. Setting
normalization = FALSE returns a variant of the declination
in radians:
An additional adjustment can be applied which takes the form:
The correction is applied by default to better allow for comparison across states, though these comparisons should be made cautiously, as always.
Simplified Declination
An simplified formulation of the declination is sometimes used to avoid using normalizing constants and arctangents. This instead looks at the difference in means of wins over the seat proportions:
with as the average Democratic voteshare in Democratic-won districts and as the average Democratic voteshare in Republican-won districts. is the Democratic seat share.
As in the declination, a negative score indicates a pro-Democratic bias and positive score indicates a pro-Republican bias.
part_decl_simple(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] -0.04681234 -0.04681234Mean-Median Score
The Mean Median Score is the difference between the mean Democratic vote share and the median Democratic district. This means that a negative score is in favor of Democrats and a positive score is in favor of Republicans. The score can range from -1 to 1.
Formally, this can be written as:
The Mean-Median score can be computed with:
part_mean_median(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] 0 0Lopsided Wins
The Lopsided Wins score indicates if a party tends to win by a larger margin than the other party. A negative score indicates a pro-Democratic bias, whereas a positive score indicates a pro-Republican bias. Scores can range from -1 to 1.
Formally, this can be written as:
with as the average Democratic voteshare in Democratic-won districts and as the average Democratic voteshare in Republican-won districts.
The Lopsided Wins score can be computed with:
part_lop_wins(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] -0.02340617 -0.02340617The output of this can be used for a t-test.
Efficiency Gap
The Efficiency Gap describes the difference in wasted votes by a party. Wasted votes are those which don’t lead to a win (votes from the party lost that district) and those which weren’t necessary for a win (the excess votes above 50% + 1 vote by the party that won the district). These are normalized by the votes for the party, leading to a score between -1 and 1. A negative score indicates a pro-Democratic bias, whereas a positive score inidcates a pro-Republican bias.
Formally, this can be written as:
with as the wasted votes by Republicans and as the wasted votes by Democrats and are the total votes.
Wasted votes can be formalized as:
$$ W_D =
{. $$
Republican wasted votes are defined analogously.
The Efficiency Gap can be computed with:
part_egap(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] -0.0201538 -0.0201538Efficiency Gap (Equal Population)
This is the efficiency gap, with the assumption that districts have equal voter turnout and population. The scale is the same as for the regular efficiency gap, where all scores are between -1 and 1, with negative implying pro-Democratic bias and positive implying pro-Republican bias.
Formally, this can be written as:
with as the seat share for Democrats.
The Efficiency Gap (Equal Population) can be computed with:
part_egap_ep(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] -0.02340617 -0.02340617Tau Gap
The gap is a generalization of the efficiency gap. When , it is exactly twice the efficiency gap. The parameter is a weighting parameter which describes how wasted votes should be weighted.
Formally, this can be written as:
where
and is defined analogously.
The Gap can be computed with:
part_tau_gap(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] -0.009275831 -0.009275831The default is tau = 1.
Dilution Asymmetry
The Dilution Asymmetry is the difference in rate of wasted votes by party. Wasted votes are as in the efficiency gap. A negative score indicates a pro-Democratic bias, whereas a positive score inidcates a pro-Republican bias.
Formally, this can be written as:
with as the wasted votes by Republicans and as the wasted votes by Democrats and and are the total votes for Democrats and Republicans, respectively.
Smoothed Seat Count Deviation
The Smoothed Seat Count Deviation offers an interpolation between seats when describing the number of seats won by a party. This can be added to the Democratic seats to describe the smoothed seat count.
As such, values are between 0 and 1, where 0 favors Republicans and 1 favors Democrats.
Formally, this is written as:
where is the Democratic vote share in Democratic-won districts and is the Democratic vote share in Republican-won districts.
The Smoothed Seat Count Deviation can be computed with:
part_sscd(plans = nh$r_2020, shp = nh, dvote = ndv, rvote = nrv)
#> [1] 0.3818761 0.3818761Ranked Marginal Deviation
The Ranked Marginal Deviation is also known as the Gerrymandering Index. Given a set of plans, we can first order them by Democratic percent in each seat. The Ranked Marginal Deviation is the square root of the sum of the squared distances between the average Democratic percent in each seat and the Democratic percent in a given plan.
Formally, this can be written as:
where is the orted Democratic voteshare in district and is the average of those across plans.
As such, it is sensitive to the plans inputted. Here we use the
nh_m data described in the “Using
redistmetrics” vignette, which contains 2 reference plans
and 50 simulated plans.
data(nh_m)
part_rmd(plans = nh_m, shp = nh, dvote = ndv, rvote = nrv)
#> [1] 0.428306762 0.428306762 24.219447110 24.219447110 2.552987343
#> [6] 2.552987343 1.807712702 1.807712702 1.430841789 1.430841789
#> [11] 0.014897340 0.014897340 0.126702397 0.126702397 0.319358751
#> [16] 0.319358751 0.243484554 0.243484554 0.372941780 0.372941780
#> [21] 0.361636666 0.361636666 0.148703808 0.148703808 1.430841789
#> [26] 1.430841789 0.243484554 0.243484554 1.327059351 1.327059351
#> [31] 0.014897340 0.014897340 0.484383034 0.484383034 1.807712702
#> [36] 1.807712702 0.509814359 0.509814359 0.837801241 0.837801241
#> [41] 0.816016501 0.816016501 0.484383034 0.484383034 4.297252277
#> [46] 4.297252277 0.350898444 0.350898444 1.094269004 1.094269004
#> [51] 0.509814359 0.509814359 0.006160546 0.006160546 0.816016501
#> [56] 0.816016501 0.509814359 0.509814359 0.412033985 0.412033985
#> [61] 0.210313258 0.210313258 0.407710508 0.407710508 0.982443775
#> [66] 0.982443775 0.126702397 0.126702397 0.432856285 0.432856285
#> [71] 2.715581106 2.715581106 0.014897340 0.014897340 1.281534954
#> [76] 1.281534954 0.574665802 0.574665802 0.484383034 0.484383034
#> [81] 0.406929519 0.406929519 0.008614078 0.008614078 0.008614078
#> [86] 0.008614078 0.361636666 0.361636666 0.350898444 0.350898444
#> [91] 0.465927075 0.465927075 1.316510943 1.316510943 1.316510943
#> [96] 1.316510943 0.465927075 0.465927075 0.803319255 0.803319255
#> [101] 2.610432184 2.610432184 1.281534954 1.281534954This score is intended for comparison, which we can display as a plot such as:
library(ggplot2)
dplyr::tibble(rmd = part_rmd(plans = nh_m, shp = nh, dvote = ndv, rvote = nrv),
plan = rep(colnames(nh_m), each = 2)) %>%
ggplot() +
geom_histogram(aes(x = rmd, fill = plan), bins = 50) +
theme_bw()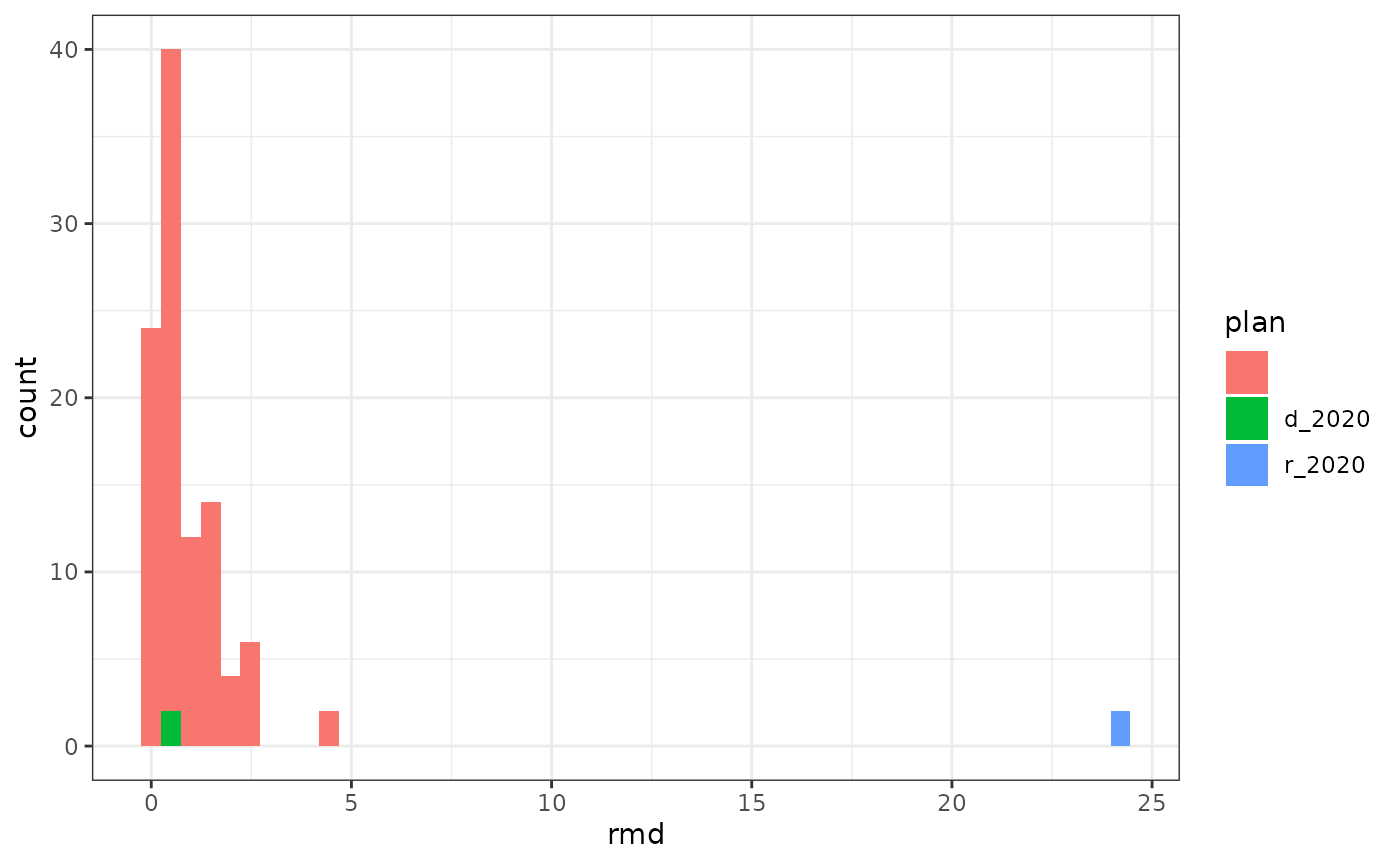
In this (small) set of simulations, the Democratic 2020 proposal is more similar to the simulated plans than the Republican 2020 proposal.
Partisan Dislocation
Partisan dislocation is a measure of how different a voter’s district is from the partisanship of their k-nearest neighbors.
Formally, this can be written as:
where denotes the k-nearest neighbors of a voter in precinct . Note that for computational reasons and to match the inputs of other functions, we do not calculate random points for each voter. Instead, we use the distance between precincts to determine the k-nearest neighbors. To create a single score for a district, we can take the mean of the partisan dislocation scores for each voter in the district. Following Deford, Eubank, and Rodden 2022, we can also take the absolute value of the partisan dislocation scores to get the partisan dislocation score for a district.